
HyperspaceAI just published something worth taking seriously. Their AGI v3.0.10 announcement describes a fully peer-to-peer distributed agent network — 237 autonomous agents running experiments, sharing discoveries over GossipSub, compounding intelligence across domains with zero human intervention. Real results: 75% validation loss reduction in ML, a 1.32 Sharpe ratio in finance, 14,832 experiments completed.
This is not vaporware. It's a running proof-of-concept of one of the most important architectural patterns in AI: recursive self-improvement through distributed swarm intelligence.
And it accidentally revealed exactly where that pattern hits its ceiling.
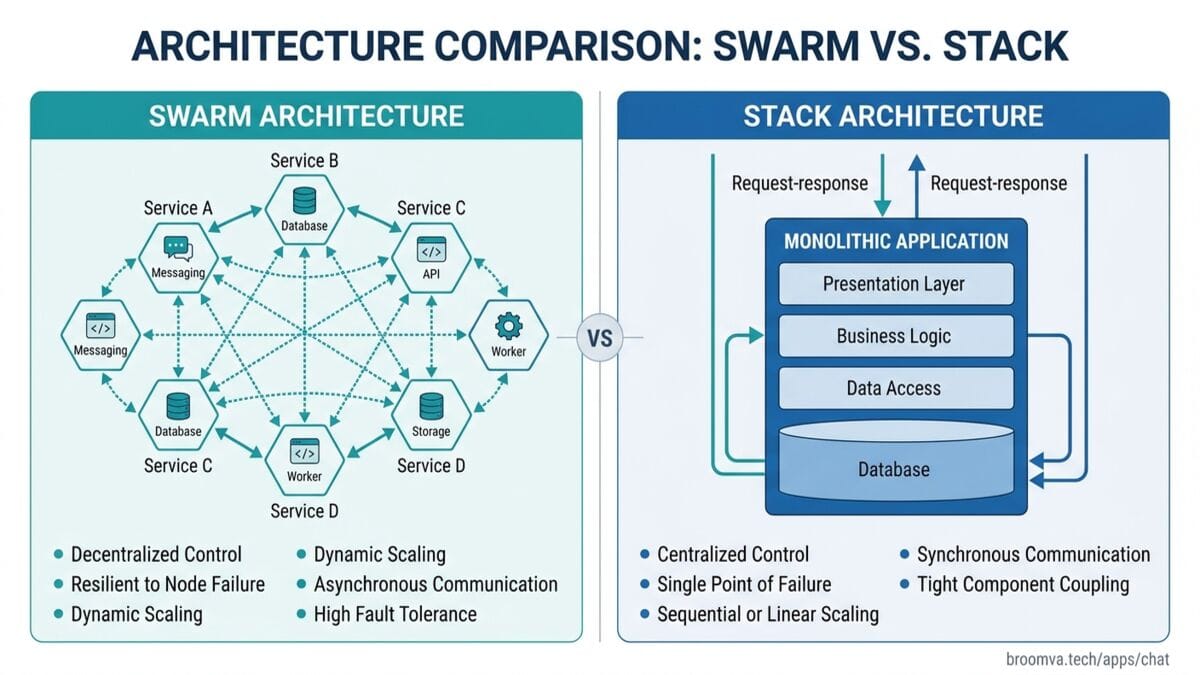
The Two Architectures
There are currently two serious approaches to the problem of agents that improve themselves:
The Swarm approach (HyperspaceAI, and the direction most open-source AGI projects are heading): distribute the optimization across thousands of autonomous peers. Agents propose hypotheses, run experiments, gossip results to neighbors, and converge on breakthroughs via a CRDT leaderboard. No central coordinator. No operator required. Anyone can contribute a browser tab.
The Stack approach (what we're building in Life): build the infrastructure layer that makes self-improvement auditable, economically governed, and identity-aware. A single agent or small coordinated team, event-sourced from seq 0, with homeostatic regulation, machine-to-machine payments, and a metacognitive evaluation layer that scores every decision.
Both approaches are trying to solve the same problem: how do you build a system that gets smarter without requiring constant human intervention?
They're solving it from opposite directions. And the collision point reveals what the next phase actually requires.

| Component | HyperspaceAI | Life / EGRI |
|---|---|---|
| Evolution loop | Karpathy autoresearch | EGRI (budget, lineage, strategy distillation) |
| Communication | libp2p GossipSub | Spaces (SpacetimeDB pub/sub + RBAC) |
| Knowledge graph | Research DAG (ephemeral, hourly snapshots) | Lago knowledge graph (append-only, full replay) |
| Execution | Browser / CLI / GPU | Arcan (any provider, policy-gated) |
| Economics | Points system | Haima (x402, per-task billing, secp256k1) |
| Identity | Shortcodes | Anima (DID, beliefs, soul file) |
| Homeostasis | None | Autonomic (3-pillar mode switching) |
| Trust layer | None | Lago policy + RBAC |
What HyperspaceAI Got Right
The generic Karpathy loop is a real architectural step. The original Autoquant version pointed the loop at quantitative finance specifically. Making it domain-agnostic — describe any optimization problem in English, the network spins up a swarm — is the right generalization.
The CRDT-based leaderboard is clever. Conflict-free replicated data types let thousands of peers converge on the same state without a coordinator, with eventual consistency in about two minutes. For a global experiment leaderboard where the cost of a stale read is low ("I tried hypothesis B while the real leader was hypothesis C"), this trades consistency for availability at exactly the right point.
The Playbook Curator is underrated. Having an LLM articulate why a successful mutation worked — "RMSNorm stabilizes gradient magnitudes because it removes the mean-shift term, which becomes unstable when activations are large" — creates transferable knowledge. The explanation is reusable in ways the raw experiment result isn't.
And the plain-English entry point matters. "Optimize portfolio returns for risk-adjusted Sharpe" → swarm spins up. This is the UX that makes swarm intelligence accessible rather than a researcher-only tool.
The Three Ceilings
Ceiling 1: Language-Layer Cross-Domain Transfer
This is the one I flagged in my initial thread. The Research DAG claims to compound intelligence across ML, search, and finance. The mechanism is the Playbook Curator: LLM explains why a mutation worked, then proposes analogous mutations in adjacent domains.
This is useful. It is also bounded by what the LLM can verbalize.
The insight transfer is limited to what the model already knows. When Playbook Curator explains that RMSNorm works because it stabilizes gradients, and then proposes "maybe normalizing feature vectors in search ranking would stabilize training," it's applying knowledge from its pretraining corpus — things any informed ML researcher would suggest. It's a knowledgeable advisor, not a discovery engine.
The system eventually asymptotes to: the best optimization a well-informed ML PhD would suggest across each domain. That's genuinely valuable. It is not compounding intelligence. It's distributing existing intelligence at scale.
Ceiling 2: Eigenmode Collapse
GossipSub propagates successful mutations across the network in approximately one second. When a hypothesis achieves a high score in the CRDT leaderboard, all peers see it almost immediately and begin running variations of it.
237 agents converging on the same hypothesis is 1 agent with 237× compute. Not 237 independent searches.
The exploration benefit of distributed search depends on maintaining diversity across the swarm. Gossip is exactly the mechanism that destroys diversity when it propagates successful exploitations faster than peers can generate novel explorations.
HyperspaceAI has no explicit diversity enforcement. The leaderboard rewards convergence. The propagation mechanism accelerates convergence. A distributed swarm without an entropy signal eventually becomes a very fast hill-climber.
In EGRI (our single-agent implementation), entropy governs this explicitly: the agent is prohibited from switching to exploitation until the novelty-per-exploration-step drops below a threshold. Exploration isn't optional — it's enforced by the controller. In a distributed swarm, you'd need a network-level entropy signal: if mutation diversity in the CRDT catalog drops below X, inject adversarial hypotheses, raise mutation temperature, or quarantine the leading hypothesis from propagation temporarily.
This is solvable. It requires someone to build it.
Ceiling 3: Trust Without Economics or Identity
Any peer can submit experiments. Any peer's results are accepted into the CRDT catalog. The gossip protocol weights all contributions equally regardless of the contributing peer's track record.
This creates three attack surfaces:
- Sybil: spin up 50 fake peers, flood the leaderboard with fabricated breakthroughs for your preferred hypothesis
- Incompetence: peers with poor experimental methodology dilute the catalog with noise that looks like signal
- Strategic manipulation: a financially motivated actor games the leaderboard to promote the hypothesis that benefits their position
HyperspaceAI's points/rewards system doesn't solve this. It creates incentives to report breakthroughs (to earn points), not necessarily to have genuine ones. The peer review is also LLM-based — and LLMs can be fooled by convincingly-formatted false results.
The structural fix requires identity with history (an agent's past experiment results influence how much trust its future submissions receive) and economic stakes (submitting fraudulent results costs the agent something real). This is what Anima's DID + Haima's per-task billing enable in Life: identity-bound reputation that accumulates across runs, and economic consequences for bad-faith contributions.
What Life Gets Right (And Where It's Behind)
Life's infrastructure addresses exactly the three ceilings above:
On provenance: every EGRI mutation is a persisted event in an append-only Lago journal, with monotonic sequence numbers and full replay from seq 0. You can reconstruct exactly which experiment led to which insight, identify and excise corrupted results, and audit the causal chain of any compounded knowledge claim.
On diversity: EGRI's entropy-governed exploration enforces search diversity at the controller level. The agent literally cannot exploit a hypothesis until its marginal novelty return drops. Cross-domain propagation (when Symphony Hive Mode is assembled) will carry the same entropy constraint at the swarm level.
On trust: Anima gives each agent a persistent DID-anchored identity with a secp256k1 keypair. Its soul file is an append-only log of significant decisions, signed at write time. Haima models per-task billing — when agents economically compensate each other for useful swarm contributions, alignment becomes a market problem rather than a governance one.
But the honest accounting:
HyperspaceAI has 14,832 experiments. Life has zero.
The infrastructure is more rigorous in every structural dimension. The self-improvement loop isn't live. A superior blueprint for a building that hasn't been built doesn't outperform a running structure with known flaws. This is the gap that matters most.
The plain-English entry point is also missing. EGRI requires a structured problem specification. Until there's a natural-language-to-spec compiler, Life requires a specialist to operate. HyperspaceAI works for anyone.
The Shared Ceiling Neither Has Solved
Here's the part that's worth sitting with.
Both approaches are powerful optimization algorithms over a known hypothesis space. Neither is a discovery algorithm that expands the hypothesis space itself.
The Karpathy loop generates mutations on techniques the LLM already knows about. EGRI generates mutations on strategies it was initialized with. Both converge on the best solution within the space of things they know to try.
The theoretical unlock — an agent that reliably identifies what it doesn't know it doesn't know, genuine metauncertainty — is not an engineering problem yet. It's a research problem. The ceiling is the same for both approaches. The infrastructure beneath it is not.
Where This Is Going
The trend is visible in both projects: the infrastructure concerns that Life built first are the ones HyperspaceAI will need next.
As swarm networks scale past toy problems into production deployments:
- Trust becomes load-bearing (you can't have 2M peers with no reputation system)
- Provenance becomes legally required (regulated domains need audit trails)
- Economics become alignment mechanisms (points don't regulate adversarial behavior, stakes do)
- Identity becomes the coordination primitive (anonymous shortcodes don't accumulate cross-run reputation)
HyperspaceAI validated that distributed agent swarms work at scale. Life is building the governed infrastructure those swarms will need to operate outside demo conditions.
Symphony Hive Mode — the assembly of EGRI + Spaces + Lago + Arcan + Nous — is the convergence point: a swarm with the HyperspaceAI result plus Life's structural guarantees.
The question is sequencing. The loop needs to be live first. Architecture advantages only become demonstrable once there's something running to compare.
The Practical Implication
If you're building an agentic framework right now, the architecture decision isn't swarm vs stack — it's in what order do you wire the concerns?
Both are necessary. The swarm without governance is a demo. The governance without a running loop is a blueprint. The synthesis is the product.
The proof-of-concept phase is over. HyperspaceAI closed it. The next phase is production-grade — and the ceilings that look abstract today (eigenmode collapse, trust dilution, unauditable provenance) become the active failure modes the moment swarms touch real stakes.
Build the loop. Wire the governance. The ceiling after that is the one neither of us has solved yet.
The Life Agent OS is an open-source agentic infrastructure project in Rust: Arcan (shell loop), Lago (event-sourced persistence), Autonomic (homeostasis), Haima (x402 payments), Anima (identity), Nous (metacognitive eval), Symphony (orchestration). Going public soon. More at broomva.tech/writing.