From Refinery to Selva
There is a solar farm outside Barrancabermeja with 50 MW of photovoltaic panels, a 20 MWh battery system, and a SCADA historian recording 10,000 data points per second. An LSTM trained on three years of this data predicts next-hour solar output with a Mean Absolute Percentage Error under 5%.
Now consider Inirida, deep in the Orinoquian selva. A community microgrid there has 200 kW of solar, a 100 kWh battery bank, and a diesel generator. There is no SCADA historian, no irradiance sensor, and no three years of anything. The national monitoring center tracks it via monthly phone calls.
The forecasting model that works in Barrancabermeja is useless in Inirida -- not because the math is wrong, but because the model was trained on data that does not exist at the target site. This is the domain adaptation problem, and solving it is the central challenge of transferring energy AI from industrial to community microgrids.

The Dual-Track Thesis
Our research operates on a deliberate dual-track strategy. Track 1 validates the full multi-agent system in data-rich environments -- NREL's National Solar Radiation Database (4 km resolution, 30-minute intervals, Americas since 1998), the UCSD Microgrid Dataset (five years of 15-minute data), IEEE benchmark systems, and XM's SiMEM platform (10,700+ million records of Colombian generation and demand).
Track 2 transfers the validated system to ZNI sites where data is scarce, connectivity is intermittent, and the operational context -- community governance, seasonal river access, subsistence economy -- has no analog in the training data. Sources shift from terabytes to kilobytes: IPSE monthly telemetry for 190 localities, PVGIS satellite estimates, NASA POWER reanalysis, and IDEAM weather stations that might be 100 kilometers away.
The gap between tracks is not a limitation. It IS the research contribution -- quantifying how models degrade when transferred from data-rich to data-scarce, and developing techniques to minimize that degradation.
What the Literature Says Works
Transfer Learning Cuts Data Needs by 80%
Wen et al. (2022) published one of the most cited papers on transfer learning for solar forecasting in Scientific Reports. Their critical finding: a model pre-trained on a data-rich solar site and fine-tuned on just two weeks of target site data achieves a 12.6% improvement in RMSE and a 16.3% improvement in forecast skill index compared to training from scratch. The practical implication is that transfer learning reduces the data requirement for a usable forecasting model from four months to two weeks -- an 80% reduction.
But the transferred model is not as good as the original. In their temporal evaluation, the source-site MAPE was 1.60% while the transferred model showed 6.25% -- roughly a 4 percentage point degradation. For microgrid dispatch, this is the difference between "excellent" and "good" on the operational quality scale. Good enough to dispatch reliably, but with wider safety margins on battery state-of-charge and more frequent unnecessary diesel starts.
Zero-Label Transfer via Adversarial Domain Adaptation
Gao et al. (2024) pushed the boundary further with Adversarial Discriminative Domain Adaptation (ADDA) for solar radiation prediction across Japanese climate zones. Their approach requires zero labeled data from the target site -- the model learns domain-invariant features through adversarial training, where a discriminator tries to distinguish source from target domain samples while the feature extractor learns to fool it.
This is directly relevant to ZNI deployment. A new site in Coqui, Choco has literally no operational history. Zero-label transfer means the system can generate forecasts on day one, using only the physical coordinates and satellite-derived irradiance as inputs.
Physics-Informed Normalization: The Highest-Impact Technique
Nie et al. (2024), published in Applied Energy, demonstrated what may be the single most impactful technique for cross-site transfer: using local clear-sky models to normalize solar output variables before transfer. The idea is elegant -- clear-sky irradiance (the theoretical maximum solar radiation at a given location and time, accounting for atmospheric effects but assuming no clouds) is computable from physics for any coordinate on Earth. By dividing actual generation by the clear-sky model, you transform the raw power signal into a "cloudiness index" that is much more transferable across sites.
The result: zero-shot transfer with physics-informed normalization produces forecasts competitive with models fine-tuned on local data. For ZNI, PVGIS provides free clear-sky data for any Colombian coordinate. This normalization strategy is immediately applicable.
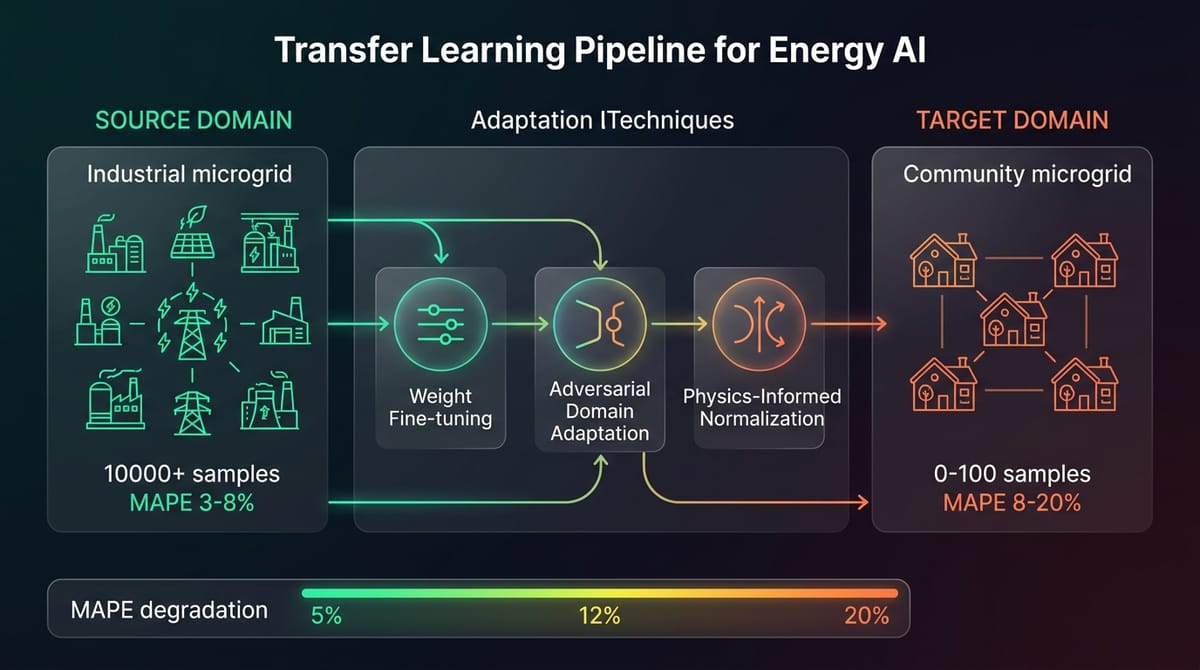
The Negative Transfer Warning
Not all transfer is positive. Li et al. (2023) demonstrated with multi-source LSTM models and Multi-Kernel Maximum Mean Discrepancy (MK-MMD) domain adaptation that while transfer learning improved MAPE by 6.88% to 15.37% in well-aligned scenarios, indiscriminate transfer across dissimilar source domains is "highly likely to result in negative transfer learning" -- where the transferred model performs worse than one trained from scratch on the limited target data.
The implication for ZNI is strict: transfer must occur within climate clusters. A model trained on Orinoquian sites (Inirida, Puerto Carreno -- high irradiance, distinct wet/dry seasons, savanna-forest transition) should transfer to other Orinoquian sites. A model trained on Pacific coast sites (Coqui, Nuqui -- low irradiance, extreme cloud cover, nearly constant rainfall) should transfer within the Pacific cluster. Cross-cluster transfer -- say, La Guajira desert irradiance patterns applied to Choco rainforest -- will almost certainly produce negative transfer.
This is not a fatal constraint. It means the fleet architecture must be climate-aware. Federated learning aggregation happens within climate zones, not across the entire fleet.
MAPE Degradation: The Honest Numbers
Here is what the literature synthesis tells us about forecasting accuracy across the transfer pipeline:
| Scenario | Typical MAPE | Data Requirement |
|---|---|---|
| Same site, 1+ year of training data | 3-8% | Full historical dataset |
| Transferred, fine-tuned, same climate cluster | 5-12% | 2 weeks of target data |
| Physics-informed zero-shot (clear-sky normalization) | 8-15% | Zero target data |
| Transferred, zero-shot, no physics normalization | 10-20% | Zero target data |
| No transfer, trained from scratch with 3 months | 15-25% | 3 months of scarce data |

The key takeaway: transfer learning consistently outperforms training from scratch with limited data. The physics-informed zero-shot approach lands in the 8-15% MAPE range, which corresponds to "acceptable" dispatch quality -- the system operates but with conservative battery margins and occasional unnecessary diesel triggers. Fine-tuning with even two weeks of local data brings this down to "good" dispatch quality.
For the proposal's ZNI pilot sites, we set realistic targets: 15% MAPE for Orinoquian and Insular sites (where satellite irradiance data is higher quality due to less cloud cover), and 25% MAPE for Pacific sites (where extreme cloud variability makes forecasting inherently harder). These are achievable with transfer; without it, the models would start at 25-40% MAPE and require months to improve.
Federated Learning on a Raspberry Pi
Once agents are deployed across multiple sites, how do they share what they learn without sharing raw data?
Each microgrid agent trains locally, computes model weight updates, and sends only those updates to a fleet coordinator. The coordinator aggregates using Federated Averaging (FedAvg) and broadcasts the improved global model. Privacy is preserved -- no raw telemetry leaves the site. Industrial partners like Ecopetrol, who will never share operational data, can still participate.
The implementation framework is Flower (Beutel et al., 2020), demonstrated running on Raspberry Pi 4 with PyTorch at 0.95 mJ per sample -- orders of magnitude less energy than desktop PCs. For a typical LSTM model (~800 KB after INT8 quantization), each sync round transmits approximately 200 KB. On a 2G/EDGE connection (50-100 kbps), that is 16-32 seconds -- feasible for daily updates.
The architecture uses opportunistic synchronization: agents accumulate updates in a disk-based queue and flush whenever connectivity appears. If the satellite link drops for three days, the agent operates autonomously. When connectivity returns, it syncs in one batch. Federated Dueling DQN research (2024) confirmed that federated RL agents outperform isolated agents in microgrid dispatch -- agents that learn from the fleet do better than agents that learn alone.
Knowledge Graphs as Data Surrogates
Here is the proposal's core innovation, and the part that has no direct precedent in the published literature.
Transfer learning addresses the statistical distribution gap between source and target domains. Physics-informed normalization addresses the physical environment gap. But neither addresses the contextual gap -- the fact that a community microgrid in Inirida operates in a social, economic, and territorial context that has no analog in the industrial training data.
Consider what a forecasting model trained on industrial data does not know about Inirida: that demand spikes on market days when fishing boats return and cold storage runs at maximum capacity; that during the dry season, the community shifts from river transport to road, changing diesel availability; that the local governance structure -- an indigenous council, not a corporate energy manager -- makes load-shedding decisions by consensus; that the school schedule determines the morning demand peak.
A knowledge graph encodes this context as structured relationships. The schema is simple and identical across industrial and ZNI deployments:
- Entities: DER (distributed energy resource), Load, WeatherStation, Community, Season, Site
- Relationships: SUPPLIES, CONSUMES, CORRELATES_WITH, NEIGHBORS, TRANSFERS_TO
- Patterns: Learned operational patterns indexed by site, season, and time
Llugiqi, Ekaputra, and Sabou (2025) demonstrated in Data Science and Management that semantically enriching training data with knowledge graph embeddings -- numerical vectors derived from the graph structure -- improves ML predictions in data-scarce scenarios. Their approach: formalize domain semantics as an ontology, construct a knowledge graph, generate embeddings, and feed those embeddings alongside tabular features into the ML pipeline.
For ZNI, the knowledge graph serves as a structured data surrogate. When the forecasting model has no historical demand curve for Inirida, it can query the graph: "What other sites share the same climate zone, population size, primary economic activity, and DER configuration?" The answer points to sites with known demand patterns, and those patterns seed the initial model.
No published work combines knowledge graphs with multi-agent systems and energy forecasting for data-scarce microgrids. This intersection -- KG as a bridge between data-rich and data-poor energy environments -- is the research gap.
What Must Change vs. What Stays Identical
What MUST change:
| Layer | Industrial | ZNI | Adaptation |
|---|---|---|---|
| Hardware | x86 server, 16-64 GB RAM | Raspberry Pi 5, 8 GB RAM | Rust runtime, 10x less power |
| Communication | OPC-UA, Ethernet, always-on | MQTT, cellular, intermittent | Store-and-forward queue |
| ML models | Float32, 10-100 MB | INT8 quantized, 1-5 MB | Knowledge distillation + quantization |
| Training data | 10,000+ samples, years of history | 100-1,000 samples, weeks of history | Transfer learning + KG augmentation |
| Protocols | Modbus TCP, IEC 61850, DNP3 | Modbus RTU, VE.Direct, GPIO | Protocol adapter trait (same Rust interface) |
What stays IDENTICAL:
- Dispatch formulation: The LP/MILP problem -- minimize cost subject to power balance, SOC limits, ramp constraints -- has the same mathematical structure at 50 MW and 50 kW. HiGHS solves both in under one second on a Raspberry Pi.
- Agent decision loop: Perceive-Predict-Optimize-Actuate runs at both scales.
- Safety constraints: SOC minimum (15-20%), genset minimum run time (15-30 min), emergency shutdown -- same structure, different parameters.
- Knowledge graph schema: Entities, relationships, and patterns are identical. Only data volume differs.
- MQTT topic hierarchy:
fleet/{region}/status,fleet/{region}/models/update,site/{site_id}/dispatch-- same for industrial and ZNI.
The architectural insight: the information model is separated from the transport protocol, the optimization from the scale parameters, and the agent loop from the hardware.
The Dual-Track Data Strategy
Track 1 (data-rich, model training): NSRDB satellite irradiance at 30-minute resolution, UCSD Microgrid Dataset for multi-DER coordination, XM/SiMEM for Colombian grid-connected generation, IEEE benchmark systems, and Pecan Street's Puerto Rico network as an island/off-grid analog.
Track 2 (data-scarce, transfer evaluation): IPSE CNM telemetry for 190 ZNI localities, NASA POWER reanalysis for any coordinate, PVGIS for clear-sky baselines, IDEAM weather stations for ground-truth, and RAMP for synthetic community load profiles.
No single dataset is sufficient. But the combination is robust. The gap between Track 1 abundance and Track 2 scarcity is not a weakness -- it is the experimental setup.
Why This Gap IS the Research Contribution
Most ML papers in energy forecasting optimize for the best possible MAPE on a well-instrumented site. The leaderboard game: beat the state of the art by half a percentage point on the same benchmark dataset.
This research asks a different question: what happens when you take that optimized model and deploy it somewhere the benchmark never imagined? Somewhere with no weather station, intermittent cellular connectivity, a knowledge base built from community interviews instead of SCADA historians, and a Raspberry Pi instead of a GPU server.
The honest answer, based on the literature, is that MAPE will degrade from 5% to somewhere between 8% and 20%, depending on the transfer technique and the climate similarity between source and target. Physics-informed normalization helps. Federated learning within climate clusters helps. Knowledge graph augmentation -- the novel contribution -- should help further, though quantifying how much is the open research question.
The research contribution is not achieving the lowest MAPE. It is building a rigorous framework for measuring and minimizing the degradation when energy AI crosses from refinery to selva.
At the end of that pipeline, a Raspberry Pi in Inirida makes dispatch decisions meaningfully better than the rule-based controller it replaced. Not perfect. But good enough to reduce diesel consumption by the 20-40% that Husk Power Systems demonstrated across 400+ mini-grids in India and Africa. Good enough to detect a failing solar panel in days instead of years. Good enough to matter.
Series Navigation
This is post 4 of 5 in the Fleet Intelligence for Renewable Microgrids series:
- Colombia's Energy Paradox: 39% Above World Average and 1.9M People in the Dark
- Fleet Intelligence: Why Microgrids Need Autonomous Agents, Not Better SCADA
- The Three-Tier Forecasting Stack: PatchTST, Foundation Models, and Why LLMs Can't Predict Power
- From Refinery to Selva: Domain Adaptation for Energy AI -- you are here
- Edge Agents in the Wild: Rust, Raspberry Pi, and Autonomous Microgrids
This is a personal open-source research project. The code is available at github.com/broomva/microgrid-agent. The architecture is designed to be built upon.